安装Hama之前,应该首先确保系统中已经安装了hadoop,本集群使用的版本为hadoop-2.3.0
一、下载及解压Hama文件
下载地址:http://www.apache.org/dyn/closer.cgi/hama,选用的是目前最新版本:hama0.6.4。解压之后的存放位置自己设定。
二、修改配置文件
- 在hama-env.sh文件中加入JAVA_HOME变量(分布式情况下,设为机器的值)
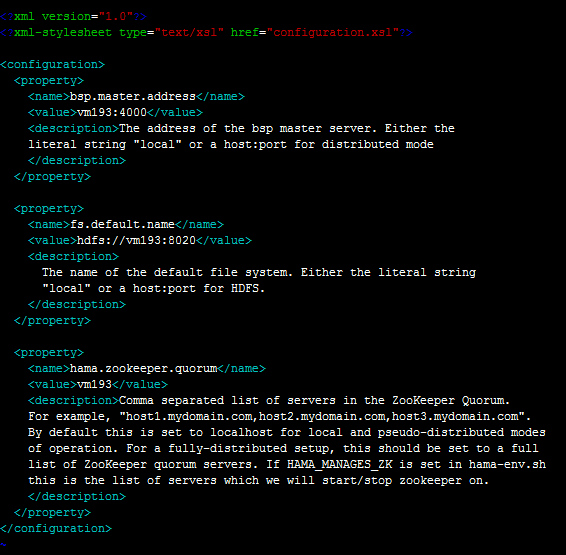
- 配置hama-site.xml(分布式情况下,所有机器的配置相同)
bsp.master.address为bsp master地址。fs.default.name参数设置成hadoop里namenode的地址。hama.zookeeper.quorum和 hama.zookeeper.property.clientPort两个参数和zookeeper有关,设置成为zookeeper的quorum server即可,单机伪分布式就是本机地址。
4. 配置groomservers文件。hama与hadoop具有相似的主从结构,该文件存放从节点的IP地址,每个IP占一行。(分布式情况下只需要配置BSPMaster所在的机器即可)
5. hama0.6.4自带的hadoop核心包为1.2.0,与集群hadoop2.3.0不一致,需要进行替换,具体是在hadoop的lib文件夹下找到hadoop-core-2.3.0*.jar和hadoop-test-2.3.0*.jar,拷贝到hama的lib目录下,并删除hadoop-core-1.2.0.jar和hadoop-test-1.2.0.jar两个文件。
6. 此时可能会报找不到类的错, 需加入缺失的jar包。(把hadoop开头的jar包和protobuf-java-2.5.0.jar导入到hama/lib下)
三、编写Hama job
在eclipse下新建Java Project,将hama安装时需要的jar包全部导入工程。
官网中计算PI的例子:


1 package pi; 2 3 import java.io.IOException; 4 import org.apache.commons.logging.Log; 5 import org.apache.commons.logging.LogFactory; 6 import org.apache.hadoop.fs.FSDataInputStream; 7 import org.apache.hadoop.fs.FileStatus; 8 import org.apache.hadoop.fs.FileSystem; 9 import org.apache.hadoop.fs.Path; 10 import org.apache.hadoop.io.DoubleWritable; 11 import org.apache.hadoop.io.IOUtils; 12 import org.apache.hadoop.io.NullWritable; 13 import org.apache.hadoop.io.Text; 14 import org.apache.hama.HamaConfiguration; 15 import org.apache.hama.bsp.BSP; 16 import org.apache.hama.bsp.BSPJob; 17 import org.apache.hama.bsp.BSPJobClient; 18 import org.apache.hama.bsp.BSPPeer; 19 import org.apache.hama.bsp.ClusterStatus; 20 import org.apache.hama.bsp.FileOutputFormat; 21 import org.apache.hama.bsp.NullInputFormat; 22 import org.apache.hama.bsp.TextOutputFormat; 23 import org.apache.hama.bsp.sync.SyncException; 24 25 public class PiEstimator { 26 private static Path TMP_OUTPUT = new Path("/tmp/pi-" 27 + System.currentTimeMillis()); 28 29 public static class MyEstimator 30 extends 31 BSP { 32 public static final Log LOG = LogFactory.getLog(MyEstimator.class); 33 private String masterTask; 34 private static final int iterations = 100000; 35 36 @Override 37 public void bsp( 38 BSPPeer peer) 39 throws IOException, SyncException, InterruptedException { 40 41 int in = 0; 42 for (int i = 0; i < iterations; i++) { 43 double x = 2.0 * Math.random() - 1.0, y = 2.0 * Math.random() - 1.0; 44 if ((Math.sqrt(x * x + y * y) < 1.0)) { 45 in++; 46 } 47 } 48 49 double data = 4.0 * in / iterations; 50 51 peer.send(masterTask, new DoubleWritable(data)); 52 peer.sync(); 53 54 if (peer.getPeerName().equals(masterTask)) { 55 double pi = 0.0; 56 int numPeers = peer.getNumCurrentMessages(); 57 DoubleWritable received; 58 while ((received = peer.getCurrentMessage()) != null) { 59 pi += received.get(); 60 } 61 62 pi = pi / numPeers; 63 peer.write(new Text("Estimated value1 of PI is"), 64 new DoubleWritable(pi)); 65 } 66 peer.sync(); 67 68 int in2 = 0; 69 for (int i = 0; i < iterations; i++) { 70 double x = 2.0 * Math.random() - 1.0, y = 2.0 * Math.random() - 1.0; 71 if ((Math.sqrt(x * x + y * y) < 1.0)) { 72 in2++; 73 } 74 } 75 76 double data2 = 4.0 * in2 / iterations; 77 78 peer.send(masterTask, new DoubleWritable(data2)); 79 peer.sync(); 80 81 if (peer.getPeerName().equals(masterTask)) { 82 double pi2 = 0.0; 83 int numPeers = peer.getNumCurrentMessages(); 84 DoubleWritable received; 85 while ((received = peer.getCurrentMessage()) != null) { 86 pi2 += received.get(); 87 } 88 89 pi2 = pi2 / numPeers; 90 peer.write(new Text("Estimated value2 of PI is"), 91 new DoubleWritable(pi2)); 92 } 93 peer.sync(); 94 95 } 96 97 @Override 98 public void setup( 99 BSPPeer peer)100 throws IOException {101 // Choose one as a master102 103 this.masterTask = peer.getPeerName(peer.getNumPeers() / 2);104 }105 106 @Override107 public void cleanup(108 BSPPeer peer)109 throws IOException {110 111 // if (peer.getPeerName().equals(masterTask)) {112 // double pi = 0.0;113 // int numPeers = peer.getNumCurrentMessages();114 // DoubleWritable received;115 // while ((received = peer.getCurrentMessage()) != null) {116 // pi += received.get();117 // }118 //119 // pi = pi / numPeers;120 // peer.write(new Text("Estimated value of PI is"),121 // new DoubleWritable(pi));122 // }123 }124 }125 126 static void printOutput(HamaConfiguration conf) throws IOException {127 FileSystem fs = FileSystem.get(conf);128 FileStatus[] files = fs.listStatus(TMP_OUTPUT);129 for (int i = 0; i < files.length; i++) {130 if (files[i].getLen() > 0) {131 FSDataInputStream in = fs.open(files[i].getPath());132 IOUtils.copyBytes(in, System.out, conf, false);133 in.close();134 break;135 }136 }137 138 fs.delete(TMP_OUTPUT, true);139 }140 141 public static void main(String[] args) throws InterruptedException,142 IOException, ClassNotFoundException {143 // BSP job configuration144 HamaConfiguration conf = new HamaConfiguration();145 BSPJob bsp = new BSPJob(conf, PiEstimator.class);146 // Set the job name147 bsp.setJobName("Pi Estimation Example");148 bsp.setBspClass(MyEstimator.class);149 bsp.setInputFormat(NullInputFormat.class);150 bsp.setOutputKeyClass(Text.class);151 bsp.setOutputValueClass(DoubleWritable.class);152 bsp.setOutputFormat(TextOutputFormat.class);153 FileOutputFormat.setOutputPath(bsp, TMP_OUTPUT);154 155 BSPJobClient jobClient = new BSPJobClient(conf);156 ClusterStatus cluster = jobClient.getClusterStatus(true);157 158 if (args.length > 0) {159 bsp.setNumBspTask(Integer.parseInt(args[0]));160 } else {161 // Set to maximum162 bsp.setNumBspTask(cluster.getMaxTasks());163 }164 165 long startTime = System.currentTimeMillis();166 167 if (bsp.waitForCompletion(true)) {168 printOutput(conf);169 System.out.println("Job Finished in "170 + (System.currentTimeMillis() - startTime) / 1000.0171 + " seconds");172 }173 }174 175 }
将工程Export成Jar文件,发到集群上运行。运行命令:
$HAMA_HOME/bin/hama jar jarName.jar
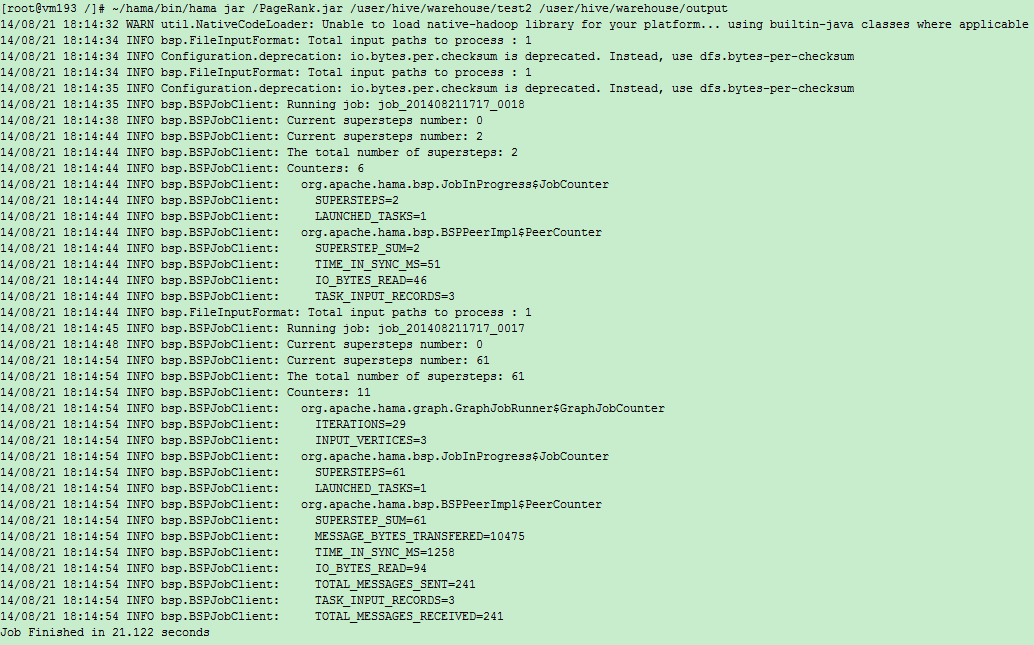
输出:
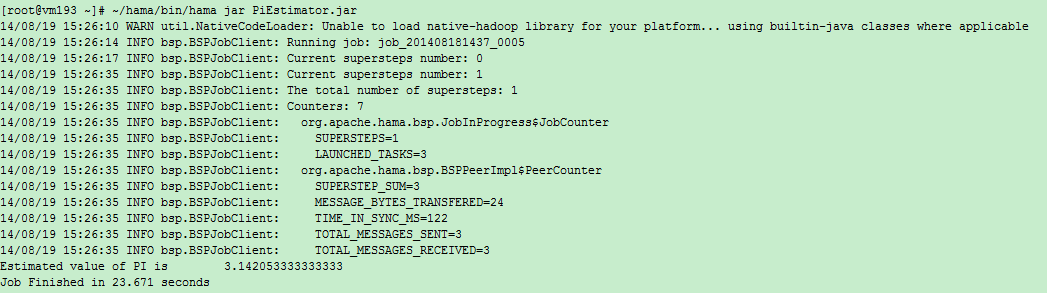
Current supersteps number: 0()
Current supersteps number: 4()
The total number of supersteps: 4(总超级步数目)
Counters: 8(一共8个计数器,如下8个。所有计数器列表待完善)
org.apache.hama.bsp.JobInProgress$JobCounter
SUPERSTEPS=4(BSPMaster超级步数目)
LAUNCHED_TASKS=3(共多少个task)
org.apache.hama.bsp.BSPPeerImpl$PeerCounter
SUPERSTEP_SUM=12(总共的超级步数目,task数目*BSPMaster超级步数目)
MESSAGE_BYTES_TRANSFERED=48(传输信息字节数)
TIME_IN_SYNC_MS=657(同步消耗时间)
TOTAL_MESSAGES_SENT=6(发送信息条数)
TOTAL_MESSAGES_RECEIVED=6(接收信息条数)
TASK_OUTPUT_RECORDS=2(任务输出记录数)
PageRank例子:
1 package pi; 2 3 import java.io.IOException; 4 5 import org.apache.hadoop.conf.Configuration; 6 import org.apache.hadoop.fs.Path; 7 import org.apache.hadoop.io.DoubleWritable; 8 import org.apache.hadoop.io.LongWritable; 9 import org.apache.hadoop.io.NullWritable; 10 import org.apache.hadoop.io.Text; 11 import org.apache.hama.HamaConfiguration; 12 import org.apache.hama.bsp.HashPartitioner; 13 import org.apache.hama.bsp.TextOutputFormat; 14 import org.apache.hama.graph.AverageAggregator; 15 import org.apache.hama.graph.Edge; 16 import org.apache.hama.graph.GraphJob; 17 import org.apache.hama.graph.Vertex; 18 import org.apache.hama.graph.VertexInputReader; 19 20 /** 21 * Real pagerank with dangling node contribution. 22 */ 23 public class PageRank { 24 25 public static class PageRankVertex extends 26 Vertex { 27 28 static double DAMPING_FACTOR = 0.85; 29 static double MAXIMUM_CONVERGENCE_ERROR = 0.001; 30 31 @Override 32 public void setup(HamaConfiguration conf) { 33 String val = conf.get("hama.pagerank.alpha"); 34 if (val != null) { 35 DAMPING_FACTOR = Double.parseDouble(val); 36 } 37 val = conf.get("hama.graph.max.convergence.error"); 38 if (val != null) { 39 MAXIMUM_CONVERGENCE_ERROR = Double.parseDouble(val); 40 } 41 } 42 43 @Override 44 public void compute(Iterable messages) 45 throws IOException { 46 // initialize this vertex to 1 / count of global vertices in this 47 // graph 48 if (this.getSuperstepCount() == 0) { 49 this.setValue(new DoubleWritable(1.0 / this.getNumVertices())); 50 } else if (this.getSuperstepCount() >= 1) { 51 double sum = 0; 52 for (DoubleWritable msg : messages) { 53 sum += msg.get(); 54 } 55 double alpha = (1.0d - DAMPING_FACTOR) / this.getNumVertices(); 56 this.setValue(new DoubleWritable(alpha + (sum * DAMPING_FACTOR))); 57 } 58 59 // if we have not reached our global error yet, then proceed. 60 DoubleWritable globalError = this.getAggregatedValue(0); 61 if (globalError != null && this.getSuperstepCount() > 2 62 && MAXIMUM_CONVERGENCE_ERROR > globalError.get()) { 63 voteToHalt(); 64 return; 65 } 66 67 // in each superstep we are going to send a new rank to our 68 // neighbours 69 sendMessageToNeighbors(new DoubleWritable(this.getValue().get() 70 / this.getEdges().size())); 71 } 72 } 73 74 public static GraphJob createJob(String[] args, HamaConfiguration conf) 75 throws IOException { 76 GraphJob pageJob = new GraphJob(conf, PageRank.class); 77 pageJob.setJobName("Pagerank"); 78 79 pageJob.setVertexClass(PageRankVertex.class); 80 pageJob.setInputPath(new Path(args[0])); 81 pageJob.setOutputPath(new Path(args[1])); 82 83 // set the defaults 84 pageJob.setMaxIteration(30); 85 pageJob.set("hama.pagerank.alpha", "0.85"); 86 // reference vertices to itself, because we don't have a dangling node 87 // contribution here 88 pageJob.set("hama.graph.self.ref", "true"); 89 pageJob.set("hama.graph.max.convergence.error", "1"); 90 91 if (args.length == 3) { 92 pageJob.setNumBspTask(Integer.parseInt(args[2])); 93 } 94 95 // error 96 pageJob.setAggregatorClass(AverageAggregator.class); 97 98 // Vertex reader 99 pageJob.setVertexInputReaderClass(PagerankTextReader.class);100 101 pageJob.setVertexIDClass(Text.class);102 pageJob.setVertexValueClass(DoubleWritable.class);103 pageJob.setEdgeValueClass(NullWritable.class);104 105 pageJob.setPartitioner(HashPartitioner.class);106 pageJob.setOutputFormat(TextOutputFormat.class);107 pageJob.setOutputKeyClass(Text.class);108 pageJob.setOutputValueClass(DoubleWritable.class);109 return pageJob;110 }111 112 private static void printUsage() {113 System.out.println("Usage:
输出: